Tableau 2020.3 has a ton of cool features coming with it, but one that hasn’t received the marketing budget it deserves is the IN operator. Tableau has always had the ability to do logic in calculated fields, but hasn’t ever had a graceful way to allow comparisons against arrays or lists. This has led customers to write all sorts of…interesting calculations.

As much as I’d love to blame customers for this, Tableau hasn’t really had a way to handle this. Sure, you could join on some lookup tables or write out the long logic string, but it should be easier. With 2020.3, Tableau calcs will now support the IN operator, making this logic easy to implement. Not only will it be easier to write, however, it will also be more performant.

When a database is passed a series of OR operators, it will have to evaluate each condition individually. This is because there’s often multiple comparisons at play. For example, take a look at the below.

In this case, different dimensions are being used for different portions of the logic statement. Because of this, the database can’t assume that the calculation can be simplified. With an IN operator, we know we’re checking a single dimension, which allows far more efficient algorithms. MySQL, for example, sorts your list and performs a binary search. As a result of this, a calculated field with a couple of completely distinct OR operations will likely show improvements, but a logic statement with many ORs in a row will yield huge returns. This means an IN operator can be orders of magnitude faster than a series of individual ORs!
Apply it to Your Server
So now we know IN is faster as well as cleaner. If you’re about to install your first Tableau instance, that’s all you need to know! But for those of you with years of Tableau workbooks behind you, how can you go back and clean them all up? Luckily, the shiny new Metadata API (MDAPI) makes this easy to do. Below is a script which uses both the MDAPI and the REST API to authenticate into your server, find the calculations which would benefit most from some re-writing, and spits out a CSV (which you should put directly back into Tableau).
To start, we need to find the formula for every calculated field on your site. Once we have these, we can figure out which ones can be optimized.
query calcs {
calculatedFields {
name
formula
datasource {
name
...on PublishedDatasource {
luid
name
vizportalUrlId
}
...on EmbeddedDatasource {
workbook {
luid
vizportalUrlId
name
}
}
}
}
}This MDAPI query returns all the info we’ll need. Information like “formula” was previously not accessible at all in Tableau. Other info, like vizportalUrlID, was only accessible through the Postgres Repository. Other more structural pieces would have been incredibly difficult to piece together using just the REST API, requiring a chain of calls. Luckily the MDAPI can give us all this info in a centralized place with a single query.
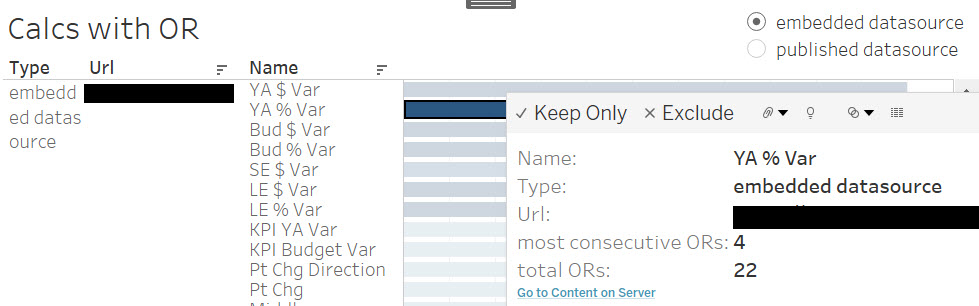
Within each calculated field, the easiest way to find optimizations was consecutive uses of the word OR. This indicates multiple comparisons that, when evaluated, all compute the same piece of information. This won’t catch every place that you could put an IN, and not every string of ORs can be replaced with an IN, but its a good starting point. To do this, we parse each calculated field to find the beginning of a logic statement (and IF or CASE statement) and count the ORs before the close of the logic statement (a THEN). A calculated field with 4 individual OR statements represents some possible optimization, but a series of 50 ORs (like the state mapping above) indicates a huge opportunity. Therefore we count both total ORs in a calculated field and highest number of consecutive ORs.
#find every instance of IF or WHEN, indicating the start of a logic string
or_instances = [m.start() for m in re.finditer('(IF|WHEN)', formula)]
or_count = []
for a in or_instances:
#find the THEN that ends the logic string
next_then = (formula.find('THEN',a))
#count the ORs in between
or_count.append(formula.count(' OR ',a, next_then))
most_ORs = max(or_count)
#compute longest string of ORs within the calc, as well as total ORs
calcs_df.at[index, 'most_ORs'] = most_ORs
calcs_df.at[index, 'total_ORs'] = sum(or_count)The rest is just string cleanup, URL creation, and getting rid of any calcs that don’t matter. It isn’t perfect (and there are some bugs in the MDAPI that surface creative results), but it gives great visibility to any site admin who wants to reach out to their end users with easy action items for faster workbooks. After all, nobody has ever complained that Tableau was too fast. Grab the script from here, build a simple workbook, put in some URL actions, and put your publishers to work speeding up your server.
For my own demo site, I found calculations which had up to 22 instances of the word OR, including logic statements with 4 ORs in a row. This was against a simple test site, nothing near what you’ll likely see in production. See what performance gains you can get on your own site!