Row Level Security: Implementing “All Access” or “Deepest Granularity” methodologies
Virtual Connections, released last year, allowed Tableau an easy way to deploy row level security at scale. You can easily build governance policies in a single place, against a single table, and have them flow down to your entire organization. These policies can be easily audited and edited as your business needs change, and you can be assured that your changes will flow down to all content living downstream of the VConn. The only remaining hurdle is figuring out the appropriate policy for your data.
Tableau’s base recommendation for RLS is to create an entitlements table with one row per user per “thing they should access”, or entitlement. A sample table might look like the below.
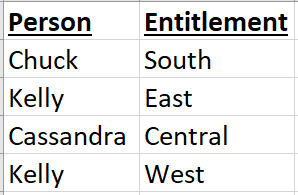
This works perfectly well for a small group of users, and even scales well as your users and entitlements grow! Where it can begin to struggle, however, is when people have access to multiple regions. I’ve written a post for managing multi-entitlement access, but there’s another type of user it didn’t account for: the superuser. Whether it’s an exec, manager, or simply an entirely different business unit (analysts, for example), there’s often a swath of users who should be able to access everything. We could individually enumerate each user and give them access to every single entitlement, but imagine a scenario in which we have 15,000 entitlements and 15,000 users. Our entitlements table could balloon to tens of millions rapidly!
The old approach, detailed in our RLS whitepaper, required joining 2 additional tables to your fact table. VConns, as currently built, only allow for a single join, so this requires a new approach. Good news, though, it’s a relatively simple approach.
- Create a group on your Tableau Server for all of your “superuser” folks. I simply called mine “Superusers”. Add all of your superusers to this group.
- Add 1 row to your entitlements table with “Superuser” in both columns.
- Modify your fact table. There are a couple things we’ll have to do here.
- Duplicate the column you use for your Entitlements join (the Region column, in my example).
- Union your table to itself.
- In the unioned copy of the table, replace all values in the Entitlements column with “Superuser”
I’ll show these modifications with some images. Consider the below fact table (only 3 rows).

I’ll union this table to itself, doubling the size (6 rows now). Add a new column for Entitlements (as a copy of the Region column). In rows 4-6, however, the Region has been replaced by the word “Superuser” in the entitlements column.

With this modified fact table, we’ll no longer need multiple joins. A single join in our VConn, with the appropriate policy, will now be sufficient to pass in all the info we need.
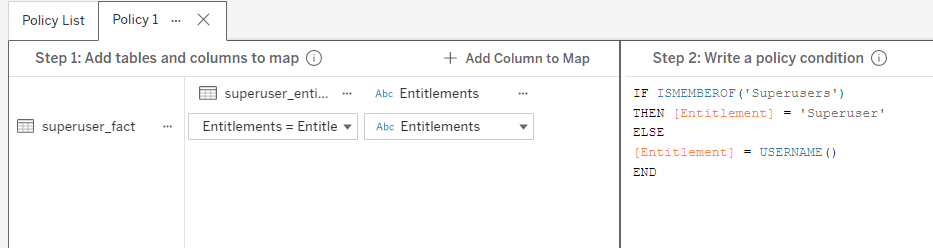
So that’s how, but why?
If all you care about is getting the work done, read no further! If you’re curious about the query execution behind the scenes because you may want to further customize this solution, read on. It might seem like a bit of a convoluted approach at first glance. The simplest approach wouldn’t seem to require any data modification at all. Why not just write a policy which checks ISMEMBEROF(‘Superuser’) and, if true, returns the whole dataset?
The answer lies in join cardinality and join culling.
First, we’ll address join culling. There’s a tendency to assume that we could write a policy like the below, and use our base entitlements table.
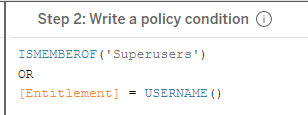
We assume that if a user passes the ISMEMBEROF() check in our policy, the entitlements join will no longer happen. We’re not using the entitlements table for anything, so why bother joining it in? The way Tableau operates, however, means that once you’ve added the entitlement table to your policy, it will always be a part of your query, even if no columns are directly referenced in the policy. No matter what happens, the tables will join and the query will execute.
But why is that a problem? That answer comes from cardinality. If each row in your dataset can only be viewed by one person, and each person can only view one row, then you’ll actually be ok with this. Unfortunately, not many businesses are that simple. Most of the time, each user can view multiple rows, and each row can be viewed by multiple people. Take the simple example below, a 5-row entitlements table. It’s the same example from the beginning, but we’ve added one more user who can see the West region.

We now have 2 copies of “West” in the Entitlements columns of the Entitlements table. If we were to join this table to our fact table and query it, we’d end up doubling all the sales from the West. In a non-Superuser experience, however, this doesn’t matter. Tableau would first query the entitlements table to the appropriate user (let’s say Kelly, in this case) and then query the joined tables.
SELECT SUM(Sales) FROM sales JOIN entitlements ON sales.entitlement = entitlement.entitlement WHERE Person = 'Kelly'The entitlements table would be filtered, the join would execute, and because there are now no duplicate values in the [entitlement.entitlement] column, no duplication occurs. Kelly sees the appropriate sales data. If, on the other hand, a Superuser logs in and queries, they’d receive the entire resulting table.
SELECT SUM(Sales) FROM sales JOIN entitlements ON sales.entitlement = entitlement.entitlementIn this case, there’s no WHERE clause, so they receive the unfiltered data. Because “West” appears twice in the [entitlement.entitlement] column, our sales in the West region get doubled. Of course, in practice, the impact will probably be much larger. There may be 5000 employees who can access the West region, and 3000 who can access the East. We’d have to do some silly math to try to reduce these numbers back to their de-duplicated state, and it would result in a lot of query overhead. Instead, we want to attempt to just query the raw, unduplicated fact table .
…and how does it work?
Really, a union is odd behavior to use here, because all we want to do is cull out the join. Because the join is unavoidable, however, we need to instead find a way to remove all duplication from the join. To do this, we unioned the fact table to itself. The duplication only happens when entitlements are joined together, so we need to make sure we don’t perform a many-to-many join. By materializing a single “Superuser” row in our entitlements table and creating a separate copy of the fact table that joins directly to it, we have effectively made a separate copy of the table for a superusers to query. The query we execute will be the same as above, but we’ve added a WHERE clause back on.
SELECT SUM(Sales) FROM sales JOIN entitlements ON sales.entitlement = entitlement.entitlement WHERE entitlement.entitlement = 'Superuser'We know that ‘Superuser’ appears only once in our entitlements table (unlike the Region values, which may be repeated). As a result of this, we know that the fact table does not get duplicated. Our superusers see all of the data, but in its unduplicated glory!

How about a concatenated list of entitlement values using CONTAINS() to evaluate? Evaluates surprisingly quickly in my experience (when using an extract). Support for array data types and unnesting would be even better 🙂
LikeLike
Huge fan of the CONTAINS() approach, and even recently saw a wonderful blog post about it, I’ll link it here!
As for how this compares, you’re right that it’s not objectively better. It does do a couple things very well though.
1. It doubles your fact table, nothing more nothing less. Your join complexity is simple, there’s no additional computational overhead, it’s simply 2x the fact table. There’s something to be said for predictability when you start the process.
2. It should be fairly technology-agnostic. Hyper has always been eerily good at CONTAINS() (except for a brief period in 10.5), but I can’t just tell everyone to extract their data. This at least uses only very standard functionality (it’s just a join) so it should work predictably against any database.
3. The entitlements are well-contained. Using a CONTAINS() function is great, but for some of our customers, they have access to 50k different entitlements (if your entitlements are stored at, for example, the level of a Salesforce opportunity). That column can get chunky in a hurry! Even if the CONTAINS() function works fairly well, having 50% of your population be encoded by a two-million-character string is dangerous.
At the end of the day, it’s horses for courses. This isn’t guaranteed to outperform CONTAINS in every situation, and I think CONTAINS() works really well when you’re talking about multiple _types_ of users. This should work really well when there’s two types of users… admins, and restricted-access users.
If you want the link for a wonderful blog I read about using CONTAINS() in newly flexible ways, check it out here. https://gunningfortableau.com/2022/06/10/multi-value-multi-column-row-level-security-solving-an-array-of-use-cases/
LikeLike