Note: We say “the customer is always right”, and this ended up being a prime example of this. My initial recommendation to run a monthly schedule can actually be better implemented, so I’ve updated the post thanks to customer feedback.
Tableau’s scheduling capabilities are limited to time-based triggers. This gives decent flexibility, but doesn’t always fit the limits of real-life ETL processes.
“We have an ETL process slated to finish at 5am. Our users have set all of their extract refreshes to be 5:15am. This is great, but if our ETL lags behind at all, it misses their refresh. They’ve realized this, so they built in a second refresh at 5:30am. And just to be safe (and because they don’t pay for the hardware), they added a third refresh at 6am. Now each of their extracts is refreshing 3x daily. Assuming this happens for every datasource, we’re looking at roughly triple our Backgrounder utilization.”
Tons of customers
Instead of having time-based scheduling, why not use the brand-new Metadata API + REST API to have ETL-based triggers? Trick your users into thinking they’re running their schedule at 5:15am like normal, but kick the extract off only when their table finishes. If your ETL finishes early, you can actually start their refresh ahead of time! If ETL finishes late, you won’t waste an extract cycle refreshing against yesterday’s data. All we need is a hook from your ETL process which outputs the table name and a simple Python file.
- Create a schedule with the cadence that you’d like. In this case, I used “Daily”. Instead of running it daily, however, disable the schedule.
- Find a hook from your ETL process. Whenever a fact table finishes its ETL process, this hook will pass the table name to a Python script.
- Use the MD API to find any published datasources containing that table.
- Use the REST API to find if those datasources are set to refresh on a given day (Daily, Weekdays, Monthly, etc)
- Refresh any extracts that meet both of the above criteria.
Let’s take a look at each of those steps in a bit more detail.
- Step 1 is easy in the Tableau UI. Create a schedule like you would for any other. Go to your Schedules pane, select the schedule, and toggle it to “Disabled”. This means tasks associated with the schedule won’t run…but people will be able to schedule tasks for this schedule.
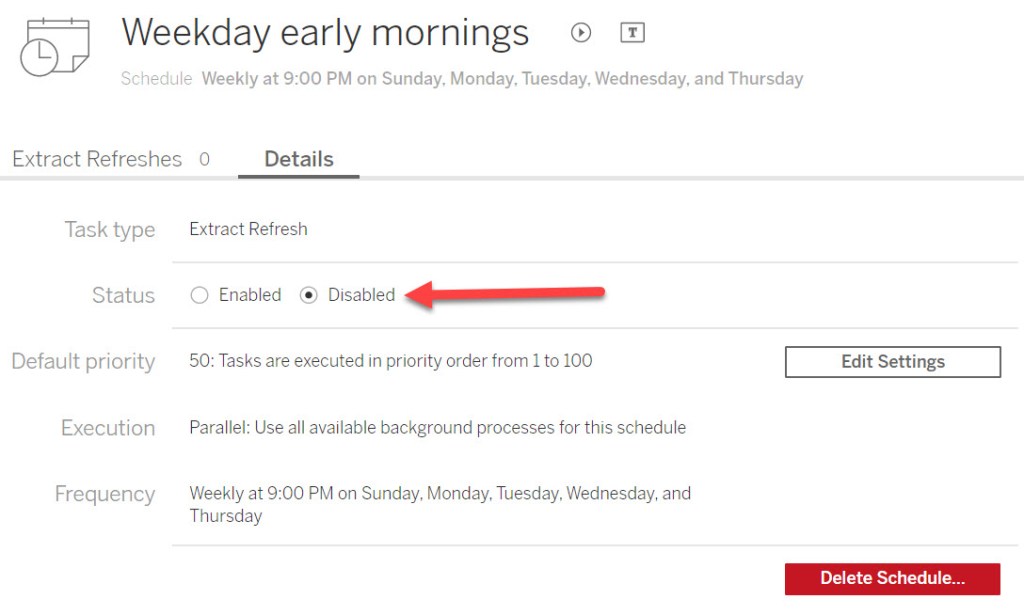
- Any ETL process should be able to, upon completing, spit out the table name. We’ll need this to let us know when to refresh each Tableau datasource.
- Using Tableau’s new metadata API, find all datasources which have your specific table name.
query relatedDatasources {
databaseTables (filter: {name: "tablename"}){
downstreamDatasources {
luid
}
}
}The above query searches your entire site for tables called “tablename”. It then looks for datasources downstream of that and returns the LUID for each one. The LUID is a unique identifier for the datasource in question. We need to run this in Python, which means either learning the odd GraphQL query syntax or copy-pasting my work.
#define our metadata api query to return datasources with our chosen table
mdapi_query = '''query relatedDatasources {
databaseTables (filter: {name: "'''+ table_name + '''"}){
downstreamDatasources {
luid
}
}
}'''
#get datasources with table
metadata_query = requests.post(ts_url + '/api/metadata/graphql', headers = auth_headers, verify=True, json = {"query": mdapi_query})
mdapi_result = json.loads(metadata_query.text)
#find the LUID for each of those datasources
for i in mdapi_result['data']['databaseTables'][0]['downstreamDatasources']:
needs_refresh.append(i['luid'])- Use the REST API to check if those LUIDs are set to refresh on the “Daily” schedule. This requires a couple of hops.
#return all schedules
schedule_list = requests.get(ts_url + '/api/3.5/schedules/', headers = auth_headers, verify=True)
schedule_list = json.loads(schedule_list.text)['schedules']['schedule']
#identify your chosen schedule
for i in schedule_list:
if i['name'] == schedule_name:
schedule_id = i['id']
print(i['name'])
#identify all associated tasks from that schedule
task_list = requests.get(ts_url + '/api/3.5/sites/' + site_id + '/schedules/' + schedule_id + '/extracts', headers = auth_headers, verify=True)
task_list = json.loads(task_list.text)['extracts']['extract']
#return the IDs of those tasks
for i in task_list:
on_schedule.append(i['id'])Find the intersection of those two lists. We want to refresh only tasks that 1. Are set to the Daily schedule and 2. Contain the table in question. This is simply finding the intersection of our two lists.
#find the intersections of datasources with the table and datasources on our schedule
run_now = list(set(needs_refresh).intersection(on_schedule))Now that we’ve got our list of tasks, there’s nothing left to do but run them. For this to work, your Server Admin must have enabled Run Now access for extracts on your TS instance.
#run tasks
for i in run_now:
requests.post(ts_url + '/api/3.5/sites/'+ site_id + '/tasks/extractRefreshes/' + i + '/runNow')That’s it!
So to put it all together, here’s what you’ll need to do. Put all of that together into one Python script (available here). Fill out the appropriate variables in that script (server URL, username, etc).
Set it up in your environment in such a way that any time an ETL process finishes on one of your fact tables, it kicks off this Python script and passes in the table name. If you have non-daily extract refresh schedules, then you’ll want to build in some date-checking as well (if you’re setting up a weekly refresh, maybe pass in the table name then check if today = Monday).
There’s some more to be done here, depending on your use case. This only refreshes published datasources, not embedded ones (pushing people towards embedded). The MDAPI query can be easily modified to fix that. Some of your users may have datasources containing multiple fact tables, so in this case it would refresh your datasource a couple of times. It may be worth building in specific logic to handle this.
Overall, this is built as a simple example of how a new feature (the Metadata API) can be a hugely powerful feature for any Server Admin to buy back a ton of CPU cycles that have been historically wasted by your business users. Enjoy!

Hi, is it possible to do the same thing for subscription? For example, I have a python script to publish a hyper data file to the server every day. There are subscription emails sending out at a specific time – which is supposed to be after the hyper data file is updated. Sometimes, the python script fails, the hyper file is failed to publish on the server. The subscription emails are still going out with old data. If possible, can you do a post on it? Thank you
LikeLike
Hey Lily, while there are workarounds that we could build in (using a dead schedule like the above + a tabcmd runschedule command), it sound like you’re really interested in the feature we just released in 2020.3. Is this what you’re looking to accomplish? https://www.tableau.com/2020-3-features#feature-135224
LikeLike