Tableau was one of the early self-service BI vendors, and has really made it’s impact by allowing any end user to not only access data, but to interact with it, ask their own questions, and build their own vizzes. The idea is to actually empower users to get what they want out of data, rather than what you prescribe.
That said, having sold Tableau for 4.5 years, I’ve come to realize that no matter how great self-service BI is, there are certain pieces of “Traditional BI” that people can’t let go of, no matter how value-less they seem. After hearing the same request enough times, sometimes you just have to cave to tradition and allow the Cognos users their one feature request.

Luckily, the 19.3 release of Tableau came with two features which make this incredibly easy. The ability to use Python in your Prep flows makes it really easy for anyone who can write Python to distribute CSVs. A 20-line Python script could distribute the relevant data to the users you want, but not everyone can write Python. The reusable steps option in Prep Builder 19.3 makes it easy to socialize this content, providing an easy skeleton for any user to use your Python flow.
The last piece of the puzzle is choosing the end users who should receive the report. By building a consistent table which can be incorporated into your flow, you can centralize this piece as well. I’ll walk through the steps below.
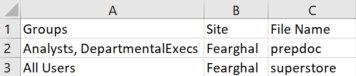
- Build a Distribution Table. This can be in a database or a simple CSV document, and should have the below structure.
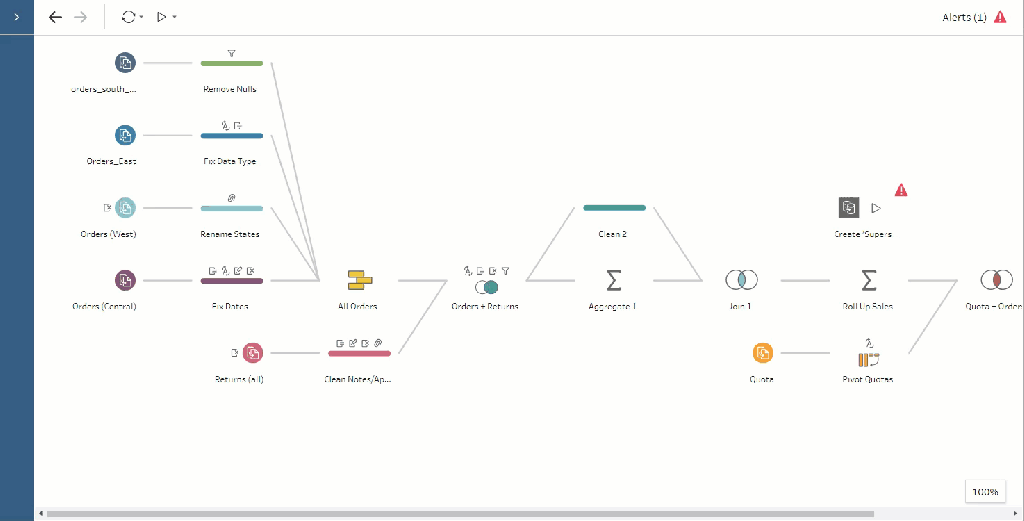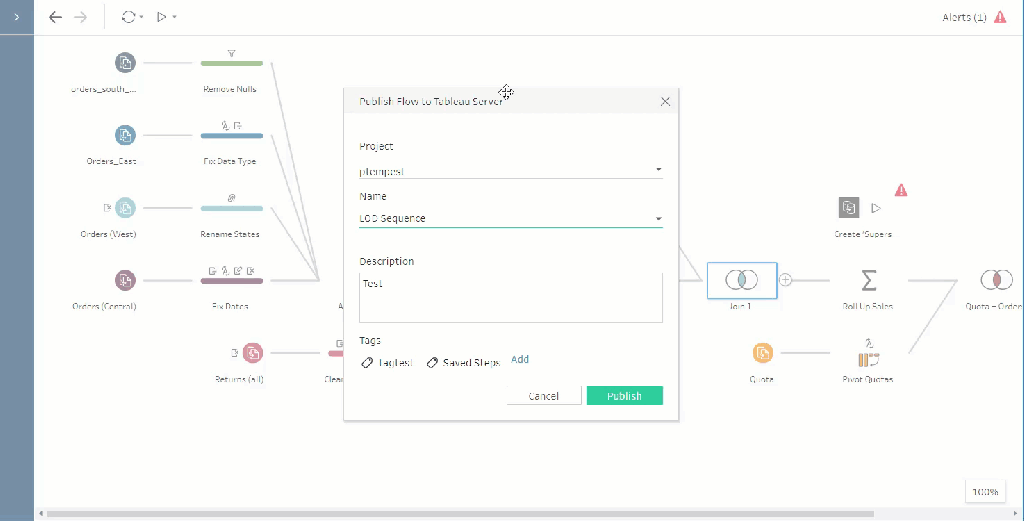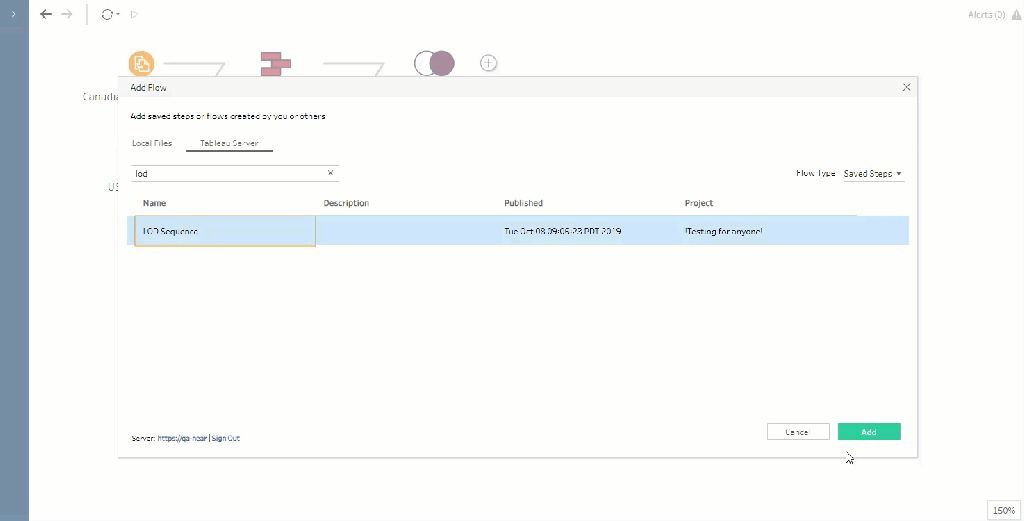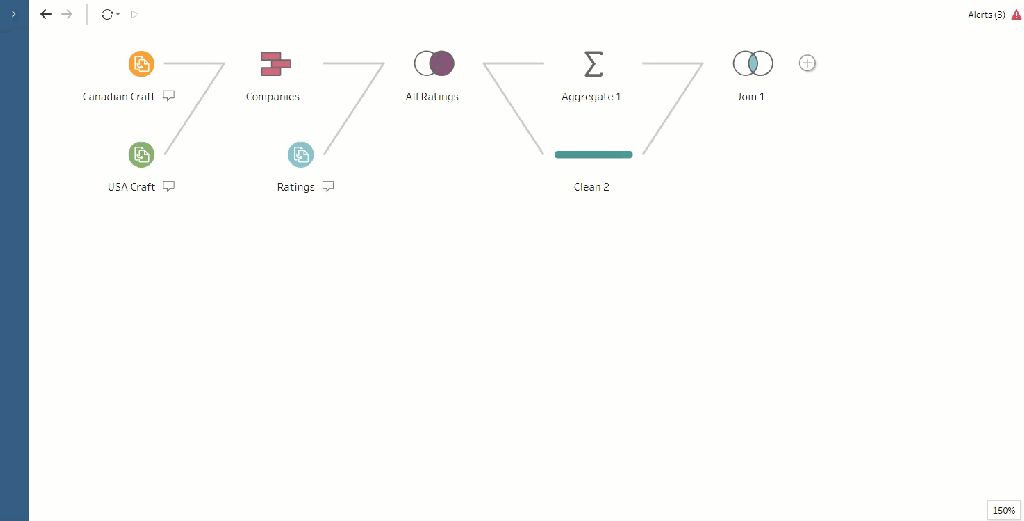
- Create a Tableau Prep flow. This can be as simple as a single file that you want to send as a CSV or it could be a 100-step Prep flow coming from 20 datasources.
- Filter your Distribution Table so it returns only one row: the desired groups for distribution.
- Join your Flow Result to your Distribution Table. There’s no matching columns here, so you’ll need to join on 1=1. This will perform a cross join, adding the Group Names to every row of your Prep Flow.
- Add a Script step (more details below).
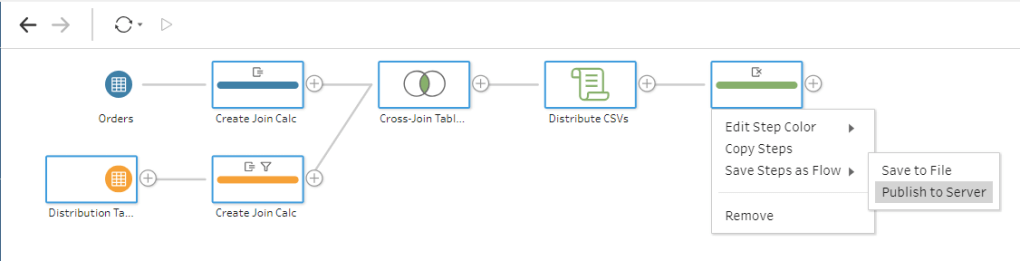
- Add an output, publish your Flow, and schedule it to refresh on the schedule of your choosing!
Once you’ve followed the above steps, Tableau will, at the appropriate interval that you’ve chosen, run your entire ETL flow, send a CSV to all of the appropriate users, and publish the .hyper file to Tableau Server. You can even make this resuable by publishing up all of the “scheduling” steps to your Tableau Server so other people can reuse it.

So what’s the magic of the Python script? It does a couple things in this case, and all of the code is available here. It does a couple of things.
- Logs in to Tableau Server.
- Gets the list of all users on the Site.
- Finds which users are in the specified Groups.
- Compiles a list of those addresses.
- Sends an email to all of those people!
I’ve broken it out into two functions.
- emailer()
- GroupMailer()
The emailer() function is pretty simple. It takes two arguments: a list of emails and a dataframe. Tableau Prep’s Python integration requires that you create a function which takes in a dataframe and returns a dataframe. In this case, we’re just taking in the data that you’d like to distribute. We do no modifications at all to it, just send it via email and return it to Tableau Prep.
The GroupMailer function is the more complex one. It leverages a couple calls from Tableau’s REST API to find all of the necessary email addresses and compile them into a list, which is then used in the emailer() function. You could, of course, create your own list of email addresses and pass that in instead.
To facilitate that, I built a separate function called PersonMailer(). It functions almost exactly like the GroupMailer() function, but allows you to pass in comma-separated email addresses instead of relying on Tableau to generate them. The downside of this is that it’s harder to scale (reports often go to thousands of users), but the upside is that these users don’t need to be licensed on Tableau Server! We’re simply using Python to send the emails out, so if you need to send it to unlicensed users, distribution lists, or dummy email addresses, this function should work perfectly for you.